Connecting a data source
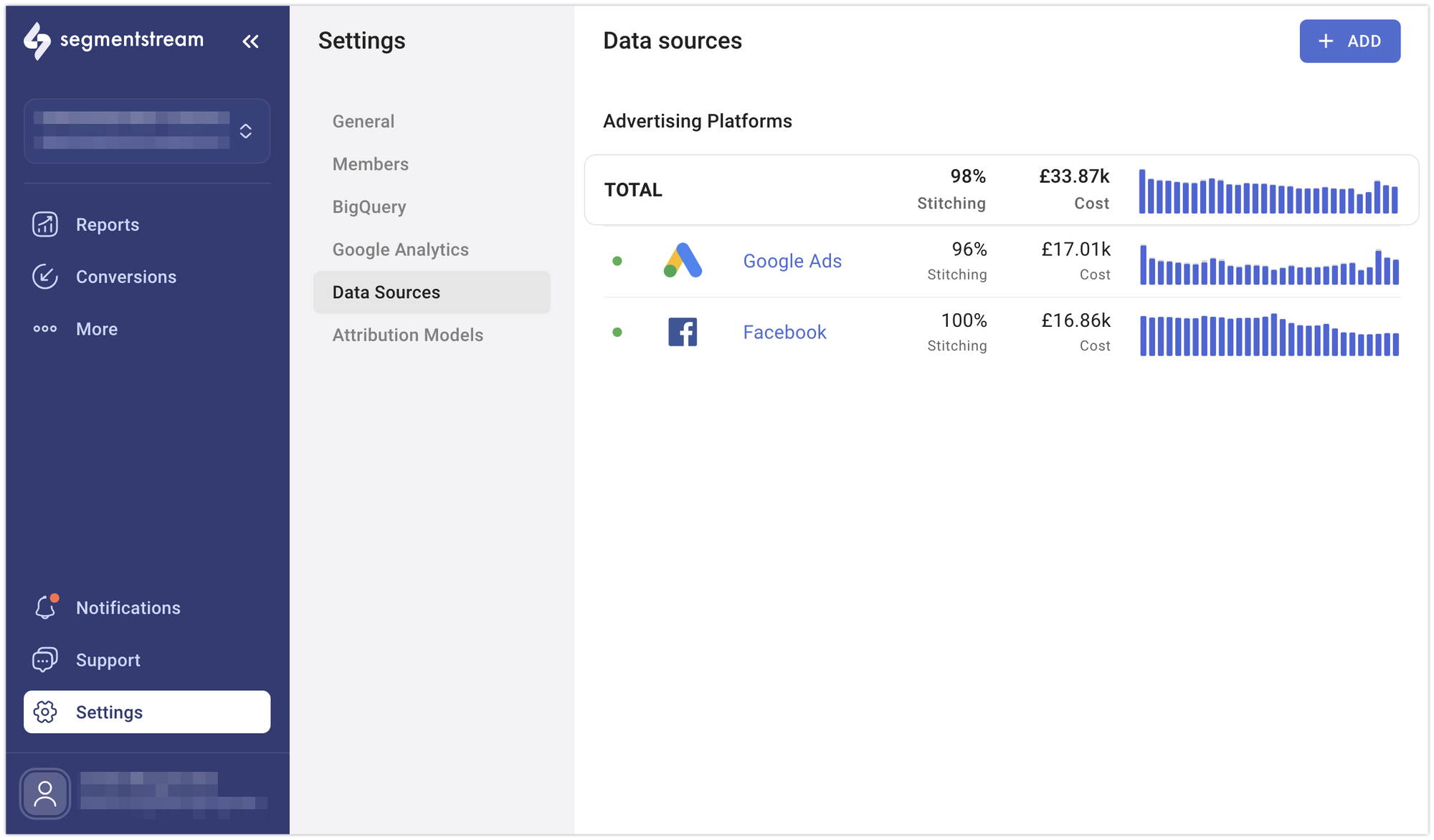
Available integrations
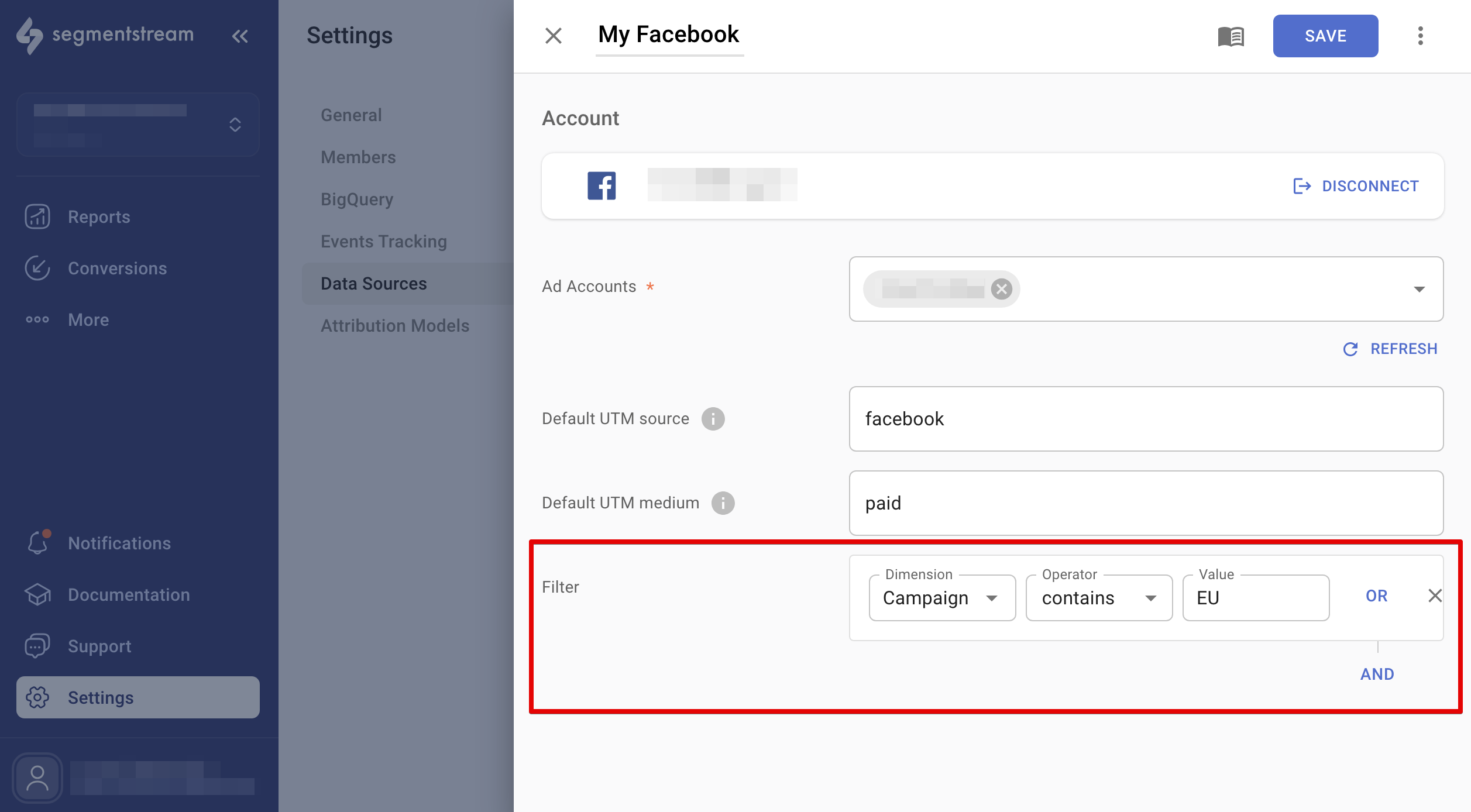
Import cost data from Facebook Ads.
Google Ads
Import cost data from Google Ads.
Microsoft Advertising
Import cost data from Microsoft Advertising.
Import cost data from LinkedIn Ads.
TikTok
Import cost data from TikTok Ads.
RTB House
Import cost data from RTB House.
Import cost data from Pinterest Ads.
Criteo
Import cost data from Criteo.
Google DV360
Import cost data from Google Display & Video 360.
Twitter (X Ads)
Import cost data from X Ads.
Awin
Import cost data from Awin.
impact.com
Import cost data from impact.com.
Google Sheets
Import cost data from Google Sheets.
Import cost data from Reddit Ads.
Snapchat
Import cost data from Snapchat Ads.
Hubspot
Import CRM data from Hubspot.
Other supported platforms
The following platforms are also available as data sources through the admin panel. They follow the standard connection process and do not require additional configuration steps:- AdRoll
- Google Campaign Manager
- OutBrain
- Quora
- Microsoft Dynamics 365
- Pipedrive
- Salesforce
- Appsflyer
- JSON Feed
- Webhook
Best practices
If you run campaigns for multiple websites using one account, you can filter out unwanted websites from reports using the data source filters. This feature works for Google Ads, Facebook Ads, TikTok, and Microsoft Ads. Adjust the settings in each data source, and the changes will reflect in reports the next day.